

In unserer heutigen Zeit haben wir uns von einmal täglichen Datenladungen in Datenlagerhäusern und Data Lakes zu 5-minütigen Micro-Batches und nahezu echtzeitnahem Streaming entwickelt. Unternehmen, die die nächste Generation von Produkten entwickeln, benötigen daher schnelle, groß angelegte Analysen mit Echtzeit-Datenentdeckung.
Das ist der Grund, warum Amundsen und DataHub, zwei der beliebtesten Metadatenarchitektur-Tools, entstanden sind. Lyft hat mit Amundsen die Produktivität seines Daten-Teams um 20% gesteigert. Ebenso hat DataHub LinkedIn dabei geholfen, Daten zu demokratisieren – 1.500 Mitarbeiter besuchen DataHub jede Woche, um Daten zu suchen, zu entdecken und für ihre Arbeit zu nutzen.
Wenn Sie versuchen herauszufinden, “Amundsen vs. DataHub – wie ähneln sie sich? Gibt es einen Unterschied?”, dann sind Sie hier genau richtig.
Amundsen vs. DataHub: Schlüsselparameter für den Vergleich
- Wie verhält sich die zugrunde liegende Architektur?
- Wie funktioniert die Metadatenaufnahme in Amundsen und DataHub?
- Bewertung der integrierten Katalog-, Linien- und Governance-Funktionen.
- Was sind die Unterschiede bei der Bereitstellung, Authentifizierung und Autorisierung?
- Was sind die Unterschiede in ihren Alleinstellungsmerkmalen (USPs) und wie sieht die zukünftige Produkt-Roadmap für Amundsen und DataHub aus?
Inhaltsverzeichnis
- Amundsen vs. DataHub: Architektur
- Datenkatalog, Linie und Governance
- Bereitstellung, Authentifizierung und Autorisierung
- Roadmaps, Updates und Community
- Amundsen vs. DataHub: Was ist das Beste für Sie?
Amundsen vs. DataHub: Vergleich der zugrunde liegenden Architektur
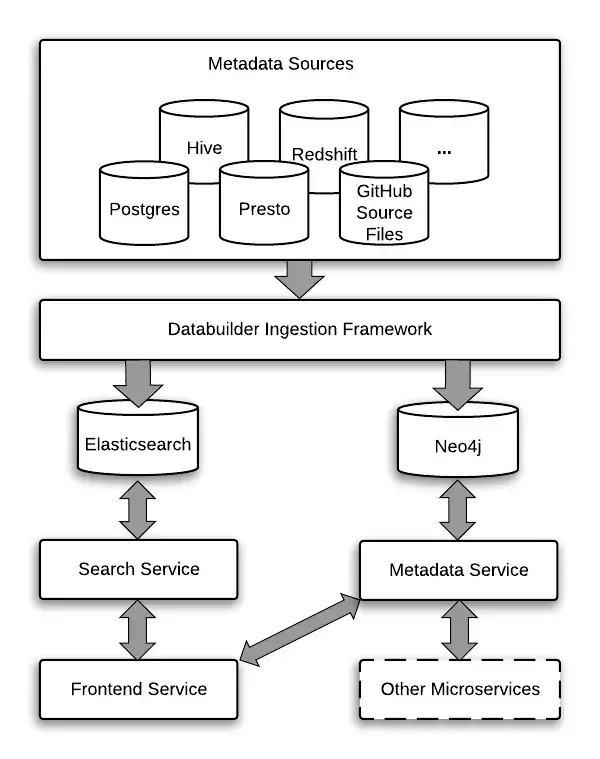
Amundsen und DataHub sind Metadatensuch- und -entdeckungstools, die mit ähnlichen Komponenten entwickelt wurden. Beide verwenden Neo4j für ihre Datenbank-Metadaten und Elasticsearch für die Metadatensuche. Sie nutzen auch eine REST-API für die Kommunikation.
Das sind jedoch die einzigen Gemeinsamkeiten. Wenn es um die Metadatenaufnahme geht, verfolgen diese Tools unterschiedliche Ansätze.
Wie funktioniert die Metadatenaufnahme in Amundsen?
Amundsen hat sein ETL-Framework und seinen Orchestrierungsmotor entwickelt, wobei es sich von Apache Gobblin hat inspirieren lassen. Es unterstützt auch eine nahtlose Integration mit Airflow.
Die Databuilder-Datenaufnahmelibrary besteht aus Extractors, Transformers und Loaders. Amundsens Databuilder unterstützt eine Vielzahl von Extractors für Python, Cassandra, Hive, Snowflake, Postgres und mehr. Das liegt daran, dass Amundsen eine Vielzahl von Datenbanken zur Speicherung von Metadaten unterstützt. Sie können auch Apache Atlas verwenden, um einen Teil des Backends und der Speicherung in Amundsen zu verwalten.
Wenn Sie den gewünschten Extractor nicht finden, können Sie Ihren eigenen erstellen und sich dabei von der generischen Extractor-Funktion inspirieren lassen. Die gleichen Konzepte gelten auch für Transformers und Loaders.

Amundsen Data Catalog Demo
Hier finden Sie eine gehostete Demo-Umgebung, die Ihnen einen guten Eindruck von der Lyft Amundsen Data Catalog Platform vermitteln sollte:
Klicken Sie hier, um Amundsen auszuprobieren
Wie unterscheidet sich die Metadatenaufnahme in DataHub von Amundsen?
DataHub verfügt über ein auf Python basierendes Metadatenaufnahmepaket, das von der kommerziellen Abteilung von DataHub – Acryl Data – gepflegt wird.
Für jede Quelle oder Senke müssen Sie das entsprechende Plugin installieren. Sie können das Python-Paket verwenden, um Metadaten mithilfe von Kafka-Ereignissen oder REST-API-Aufrufen aufzunehmen. Dieses Paket integriert sich nahtlos mit dem DataHub-CLI-Tool. Alternativ können Sie das acryl-datahub Paket in Ihrer benutzerdefinierten Python-Bibliothek verwenden. Für komplexe oder zeitgesteuerte Workflows können Sie dieses Paket problemlos mit Airflow integrieren.
Neben REST-API unterstützt DataHub auch GraphQL und eine AVRO-basierte API über Kafka zur Kommunikation zwischen den verschiedenen Elementen seiner Architektur.

Das haben wir bisher besprochen:
| Tool | Datenbank | Suche | Aufnahme | Service-Kommunikation |
|---|---|---|---|---|
| Amundsen | neo4j | Elasticsearch | Databuilder, REST API | REST API |
| DataHub | neo4j / MySQL | Elasticsearch | Plugin-basiert, REST API, GraphQL, Kafka | REST API, GraphQL, Kafka |
Als nächstes schauen wir uns an, wie sich ihre Funktionen voneinander unterscheiden.
Amundsen vs. DataHub: Datenkatalog, Linie und Governance
Sowohl Amundsen als auch DataHub unterstützen Anwendungsfälle für:
- Suche und Entdeckung: Die Metadatensuche und -entdeckung erfolgt über eine zentrale Plattform, die mit einer Vielzahl von Quellen integriert ist.
- Linie: Sie können den Ursprung, die Bewegung und die Entwicklung der Daten für Compliance und geschäftlichen Kontext verfolgen.
- Governance: Sie können feingranulare Richtlinien festlegen, um den Zugriff auf Informationen zu kontrollieren. Darüber hinaus basiert die Datenklassifizierung auf verschiedenen internen Geschäftsregeln und globalen regulatorischen Standards (DSGVO, CCPA).
- Qualität: Sie können Geschäftsregeln konfigurieren, die die Datenqualität definieren, und Qualitätssicherungsintegrationen, Berichte und Dashboards mit externen Tools einrichten.
Neben diesen Anwendungsfällen unterstützen beide Tools auch mehrere Aufnahmequellen und Dashboard-Connectors.
Amundsen hat beispielsweise über zwanzig Datenbank-Connectors für die Aufnahme und mehrere Dashboard-Connectors. Mit der Unterstützung von generischen Connectors wie AWS Glue und einem Dashboard wie Superset ermöglicht Amundsen eine große Erweiterbarkeit, ohne dass eigene Connectors geschrieben werden müssen.
DataHub hingegen verfügt über eine Vielzahl von Aufnahmequellen, Dashboard-Connectors, ML-Integrationen, Pipelines und anderen Funktionen für die Metadatensuche und -entdeckung.
Erfahren Sie mehr: Top-Anwendungsfälle für Datenkataloge, die für datenbasierte Unternehmen unverzichtbar sind
LinkedIn DataHub Demo
Hier finden Sie eine gehostete Demo-Umgebung, in der Sie DataHub – die Open-Source-Metadatenplattform von LinkedIn – ausprobieren können.
Klicken Sie hier, um DataHub auszuprobieren
Amundsen vs. DataHub: Schlüsselunterschiede und Alleinstellungsmerkmale (USPs)
Amundsen ist einfach zu verstehen, zu installieren, zu modifizieren und zu implementieren. Die Haupt-Unique Selling Points (USPs) sind:
- Backend-Unterstützung: Amundsen ist in Bezug auf die Backend-Unterstützung fortschrittlicher als andere Tools. Neben Neo4j, das das Standard-Backend für Amundsen ist, unterstützt es auch AWS Neptune und Apache Atlas als Backend-Umgebungen.
- Vorschauen: Diese Funktion ist ziemlich einzigartig. Mit der Vorschau können Sie Ihren Metadatenkatalog mit einer Live-Datenbank verbinden und eine Beispielmengen von Daten anzeigen, um mehr Kontext zu erhalten.
Hier ist, was der Mitbegründer von Amundsen zu sagen hat, wenn er das Tool mit DataHub vergleicht.
DataHubs Stärken liegen hingegen in seinen Fähigkeiten zur Daten-Governance. Dazu gehören:
- Feinere Zugriffskontrollen: DataHub unterstützt die Klassifizierung auf Spalten- und Datensatzebene, PII-Markierungen, automatisches Löschen von Daten (um die DSGVO einzuhalten) und vieles mehr.
- Datenlinie: In seiner Roadmap verspricht DataHub eine Spaltenlinienzuordnung und Integration mit Test-Frameworks wie Great Expectations, dbt test und deequ.
Obwohl DataHub im Gegensatz zu Amundsen keine Unterstützung für mehrere Backend-Umgebungen bietet, steht diese Funktion auf der Roadmap von DataHub als Priorität.
Hier ist, wie einer der Gründer von DataHub es von Amundsen unterscheidet.
| Funktion | Amundsen | DataHub |
|---|---|---|
| Suche und Entdeckung | Ja | Ja |
| OIDC/OAuth | Ja | Ja |
| Unterstützung für Airflow | Ja | Ja |
| Unterstützung für dbt | Ja | Ja |
| Unterstützung für mehrere Backends | Ja | Nein |
| Tabellenlinie | Ja | Ja |
| Spaltenlinie | Ja | Nein |
| Klassifizierung und Markierung | Ja | Ja |
| Feingranulare Zugriffskontrolle | Nein | Ja |
Amundsen vs. DataHub: Bereitstellung, Authentifizierung und Autorisierung
Beide Tools können leicht mit Binärdateien erstellt und bereitgestellt werden. Wenn Sie jedoch einen schnellen und einfachen Start wünschen, können Sie sie auf Docker ausführen.
Die einzige Voraussetzung – Sie benötigen Docker und Docker Compose sowie die Python- oder Node.js-Versionen. Wenn Sie Hilfe bei der Bereitstellung dieser Tools benötigen, finden Sie hier einige Schritt-für-Schritt-Anleitungen:
- Einrichtung des Amundsen-Datenkatalogs
- Einrichtung des DataHub-Datenkatalogs
Amundsen vs. DataHub: Roadmaps, Updates und Community
Beide Projekte verfügen über eine öffentliche Roadmap und umfangreiche Community-Unterstützung, der Sie folgen können.
Amundsen pflegt eine Zusammenfassungsseite für die Roadmap sowie eine GitHub-Issues-Seite, auf der Sie genau sehen können, woran gerade gearbeitet wird. Darüber hinaus können Sie sich aktiv beteiligen, indem Sie:
- Zum Projekt auf GitHub beitragen, indem Sie sich die mit “gutes erstes Problem” gekennzeichneten Issues schnappen
- Amundsen’s monatliche Updates auf Medium abonnieren
- Dem Blog von Stemma folgen
Genau wie Amundsen unterhält auch DataHub eine Produkt-Roadmap und teilt regelmäßige Updates auf Medium.
Amundsen vs. DataHub: Was ist das Beste für Sie?
Obwohl es viele Metadatensuch- und -entdeckungstools gibt, ist es schwer, die perfekte Lösung zu finden. Das beste Tool ist dasjenige, das Ihren Geschäftsanforderungen entspricht und nahtlos in Ihren Technologie-Stack integriert werden kann.
Um alles zusammenzufassen, haben wir eine Feature-Matrix erstellt, die die Fähigkeiten beider Tools hervorhebt.
| Tool | Amundsen | DataHub |
|---|---|---|
| Entwickelt von | Lyft | |
| Architektur | ETL-basierte Metadatenaufnahme | Plugin-basierte Metadatenaufnahme |
| Features | 1. Einfach einzurichten, zu modifizieren und bereitzustellen 2. Suche und Entdeckung 3. Unterstützung für mehrere Backends 4. Datenlinie (Tabellen und Spalten) 5. Datenklassifizierung und Markierung |
1. Suche und Entdeckung 2. Integration mit dem Stream-Ecosystem über Kafka und Unterstützung von GraphQL 3. Datenlinie (spaltenbasierte Linie ist in der Roadmap) 4. Feingranulare Zugriffskontrolle 5. Datenklassifizierung und Markierung |
| Bereitstellung | 1. Kubernetes 2. AWS ECS 3. Standalone Docker |
1. Kubernetes 2. Google Cloud GKE (Google Kubernetes Engine) 3. Standalone Docker |
| Authentifizierung | OAuth OIDC (OpenID Connect) | 1. OAuth OIDC 2. JaaS (Java Authentication and Authorization Service) |
| Autorisierung | In der Roadmap | Plattform- und Metadatenrichtlinien |
| Roadmap und Updates | 1. Amundsen Roadmap 2. Updates auf Medium und Stemma 3. GitHub (ermöglicht auch die Beteiligung) |
1. DataHub Roadmap 2. Updates auf Medium |
Suchen Sie nach einer sofort einsatzbereiten Alternative mit der Agilität und Skalierbarkeit von Open-Source-Datenkatalogen? Dann testen Sie Atlan.
Prodkt-Tour ansehen
Foto von Christina Morillo auf Pexel