

Du interessierst dich für die Unterschiede zwischen synchroner und asynchroner Programmierung? In diesem Artikel erfährst du, wann du welche Methode einsetzen solltest. Basierend auf einem beliebten Low-Code-Plattform-Beispiel zeige ich dir, wie du ein System entwirfst, das asynchron läuft. Lass uns ohne weiteres Zögern loslegen!
Solltest du dich für asynchrone Programmierung entscheiden?
Kurz gesagt: Nein. Obwohl es zahlreiche Vorteile gibt, sollten nicht alle Prozesse parallelisiert und asynchron ausgeführt werden. Es ist wichtig zu verstehen, wann asynchrone Programmierung angewendet werden sollte und wann eine synchrone Ausführung die beste Option ist.
Stell dir vor, du hast die folgende Abbildung vor dir. Oben kannst du sehen, dass bei einer synchronen Ausführung die Aufgaben sequenziell abgearbeitet werden. Zuerst werden die Produkte bearbeitet, dann die Kunden und schließlich die Aufträge.

Angenommen, du kommst zu dem Schluss, dass Kunden und Produkte unabhängig voneinander sind, aber für die Ausführung von Aufträgen Informationen über Produkte benötigt werden. Hier liegt eine Abhängigkeit vor. In diesem Fall können die ersten beiden Aufgaben asynchron ausgeführt werden, aber Aufträge können nur dann ausgeführt werden, wenn Produkte abgeschlossen sind – also müssen sie synchron arbeiten.
Durch die Anwendung von parallelem Computing und asynchroner Programmierung bei der Bearbeitung unabhängiger Aufgaben kannst du diese Aufgaben viel schneller als bei synchroner Ausführung erledigen, da sie gleichzeitig ausgeführt werden. Dadurch werden wertvolle Ressourcen früher freigegeben und das System ist bereit, andere Prozesse schneller abzuarbeiten.
Wie entwirft man ein asynchrones System?
Das Entwerfen eines Systems, das den Prinzipien der asynchronen Programmierung folgt, kann ziemlich komplex sein. Deshalb zeige ich dir jetzt anhand eines typischen Schadensabwicklungsportals, wie du das mit einer Low-Code-Plattform – wie OutSystems – machen kannst. Wenn du kein OutSystems-Entwickler oder -Architekt bist, kannst du diese Anleitung dennoch nutzen, um parallele asynchrone Prozesse mit deiner bevorzugten Technologie zu automatisieren.
Hier haben wir also das Portal, das von Versicherungsnehmern und anderen Parteien genutzt wird, um Schadensinformationen einzugeben und zu verwalten. Dieses Portal kommuniziert über eine API mit einem Schadenvalidierungssystem.
Wenn wir genauer hinschauen, importiert das Validierungssystem Daten in eine Business-Validierungsengine, die einen Broker und Geschäftsregeln umfasst. Die Prozesse und Logik dieser Engine sind unabhängig von externen Systemen. Danach integriert sich dieses System mit Zahlungskanälen, an die es die Ergebnisse der Geschäftsvalidierung exportiert.
Bevor wir zur eigentlichen Implementierung kommen, möchte ich einige Begriffe und Funktionen klären, die ich verwende, da ich OutSystems benutze. Wenn du bereits damit vertraut bist oder einfach nur die vorgeschlagene Architektur sehen möchtest, um die Effizienz dieses Schadensportals zu verbessern, kannst du zum nächsten Abschnitt übergehen.
Automatisierung asynchroner Prozesse in einem Schadensabwicklungsportal: Vorgeschlagene Architektur
Schauen wir uns das Schadenvalidierungssystem genauer an:
Die API fügt jeden der Schäden in eine Zwischendatentabelle (staging data) ein. Anschließend sucht ein geplanter Timer in regelmäßigen Abständen nach diesen Schäden. Beachte, dass jeder Schaden eine Struktur ist, die mehrere Datensätze enthalten kann. Der Timer validiert und zerlegt diese Schäden und Datensätze und führt einen Bulk Insert in die Business-Entitäten für die Schadensfälle durch.
Um unsere Ressourcen so gut wie möglich zu optimieren, verarbeiten wir nicht jeden Datensatz, sobald er in die Tabelle eingefügt wurde. Wir möchten außerdem den Overhead des Startens eines Validierungsprozesses vermeiden. Daher verwenden wir eine sogenannte “Bucket Control”, was im Grunde ein Datensatz ist, in dem wir angeben, welcher der Anfangsdatensatz und welcher der Enddatensatz ist. Diese Bucket Control ist also ein Intervall von Datensätzen und Schäden, die verarbeitet werden sollen.
Für jeden Datensatz in einem Bucket triggern wir einen leichten Prozess, der jeden einzelnen Datensatz in diesem Bucket verarbeitet. Mit “Verarbeitung” meine ich die Anwendung der Regeln. Diese Regeln sind Engines, die flexibel einsetzbar sind und zur Laufzeit in das System integriert werden können.
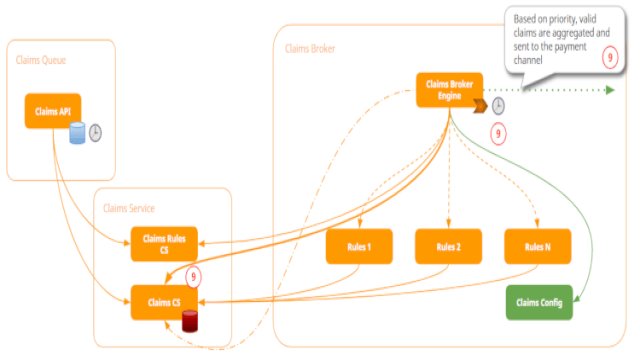
Wenn ein Datensatz gemäß den Geschäftsregeln als gültig betrachtet wird, wird er entsprechend markiert und ein Timer aggregiert die Daten und sendet sie entsprechend an den Zahlungskanal.
Hier ist also unsere vorgeschlagene Architektur:
Zunächst sammelt die Claims API alle Daten, die über eine JSON-Struktur oder XML importiert werden. Jede Daten werden dann in die Zwischentabelle eingefügt. Das Ziel hierbei ist es, die Datenübertragung zu beschleunigen und Datenverluste zu vermeiden.
Sobald die Daten eingefügt sind, wird ein Timer zu festgelegten Zeiten gestartet. Der Zweck dieses Timers besteht darin, die Schäden basierend auf zuvor definierten Schadenregeln zu zerlegen und einen Bulk Insert durchzuführen. Basierend auf diesen Regeln werden die Schäden im Schadensservice eingefügt.
Die Anzahl der Datensätze in jedem Bulk ist die Anzahl der Datensätze, die du innerhalb eines Zeitlimits von drei Minuten verarbeiten kannst. An diesem Punkt solltest du vermeiden, noch verfügbare parallele Kapazitäten zu haben und nur einen leichten Prozess gleichzeitig auszuführen, da du einen Bucket mit einer großen Anzahl von Schäden spezifizierst.
Sobald die Bucket Control erstellt ist, wird ein leichter Prozess ausgelöst.

Dieser Auslöser führt den Prozess aus.
Als Ergebnis jeder Regel wird ein Schaden als “gültig” betrachtet und geht somit zum nächsten Schritt über oder wird als “ungültig” gekennzeichnet und in diesem Fall vom System abgelehnt.
Schließlich wird das System über einen Timer, der nach Priorität geplant ist, alle gültigen Schäden abrufen, aggregieren und sie an Zahlungskanäle senden.
Du kannst die Priorisierungsregeln auch komplexer gestalten. Beispielsweise kannst du festlegen, dass bestimmte Schäden so schnell wie möglich gesendet werden sollen, damit sie direkt nach der Validierung bereit zur Zahlung sind. Oder du kannst bestimmte Schäden als Niedrigpriorität definieren, die dann vom Timer verarbeitet werden können.
Ein weiterer Vorteil dieser schrittweisen Regeln in der Engine besteht darin, dass das System auch von einem Timeout oder einem Absturz wiederhergestellt werden kann. Stell dir vor, dass nach der Verarbeitung von Regel eins, aber vor der Ausführung von Regel zwei, ein Timeout oder ein katastrophaler Fehler im Prozess auftritt und das System sich davon erholen muss. Mit diesem System steht jeder einzelne Schaden an genau dem Punkt zur Verfügung, an dem er vor dem Vorfall war. In diesem Fall würde der Schaden sich erholen und Regel zwei anstelle von Regel eins ausführen.
Schlussfolgerungen
Ich hoffe, dieser Artikel hat dir geholfen, alle Fragen zu klären, die du bezüglich der Verwendung von asynchroner oder synchroner Programmierung hast. Hier sind die wichtigsten Punkte, die du dir merken solltest:
- Verwende die asynchronen Techniken, die am besten zum gewünschten Ergebnis passen.
- Skaliere Front-End-Server und Konfigurationen nach Bedarf. Wenn du Millionen von Datensätzen hast, benötigst du mehr Front-End-Server, um deine Anforderungen zu erfüllen.
- Entwerfe mit Flexibilität im Hinterkopf und vermeide harte Codierung oder feste Werte. Stell dir vor, du verwendest feste Werte für die Bucket Control. Wenn dein Schadensvalidierungsprozess langsamer wird und du es nicht bemerkst, treten Timeouts auf. Nun bist du in einer noch schlechteren Situation, weil du die Änderungen veröffentlichen musst und nicht ins Back-Office gehen kannst, um sie zu ändern.
- Überkompliziere nicht. Versuche, deine Architektur und dein System so einfach wie möglich zu halten.
Wenn du dieses Szenario in Aktion sehen möchtest, schau dir meinen aktuellen TechTalk an: “How to Use Asynchronous Techniques in OutSystems”. Dort zeige ich dir die hier vorgeschlagene Lösung und nutze gleichzeitig die asynchronen Möglichkeiten von OutSystems, um Skalierbarkeit und Ausfallsicherheit zu fördern und große Datenmengen zu bewältigen.