

Hast du dich jemals gefragt, wie Unternehmen ihre Daten effizient sammeln, speichern und integrieren, um betriebliche Vorteile zu erzielen? Oder wie Datenanalysten, Datenwissenschaftler, Ingenieure und Manager zuverlässige Datenspeicherlösungen verwenden, um Berichte zu erstellen und Analysen durchzuführen? In diesem Artikel werden wir die Unterschiede und Vorteile von Datenbanken, Data Warehouses und Data Lakes kennenlernen.
Datenbanken
Eine Datenbank ist ein Ort, an dem verwandte Daten gespeichert und für Analysen und andere Zwecke genutzt werden. Es gibt verschiedene Arten von Datenbanken, wie strukturierte relationale Datenbankmanagementsysteme (RDBMS) und unstrukturierte NoSQL-Datenbanken. Datenbanken sind spezialisierte Speicherplätze für unverarbeitete Transaktionsdaten und werden häufig für Finanzberichte, Datenauswertung und Automatisierung verwendet.
Datenbanken im Einsatz
Einige der am häufigsten verwendeten Datenbanken sind PostgreSQL, MySQL, MongoDB und Oracle. PostgreSQL ist ein objektrelationales Datenbankmanagementsystem, das zusätzlich zu seiner relationalen Form auch objektorientierte Programmierung unterstützt. MySQL ist ein vollständiges Datenbankverwaltungssystem, das aufgrund seines relationalen Modells und seiner einfachen Verständlichkeit beliebt ist. MongoDB hingegen ist eine nicht relationale Datenbank, die ein Dokumentdatenmodell verwendet und gut mit Cloud-Computing-Apps funktioniert. Oracle ist eine weit verbreitete Datenbank mit einer Vielzahl von Funktionen, die auch nicht relationale Modellierungsansätze unterstützt.
Data Warehouses
Ein Data Warehouse ist mehr als nur eine große Datenbank. Im Gegensatz zu Datenbanken, die sich auf schnelle Lese- und Schreibaktivitäten konzentrieren, sind Data Warehouses auf umfangreiche Datenanalysen spezialisiert. Sie speichern Datensätze aus verschiedenen Quellen und ermöglichen es Unternehmen, Analysen auf kombinierten Daten durchzuführen. Data Warehouses unterstützen die Verarbeitung großer Datenmengen und sind mit OLAP- und BI-Tools kompatibel.
Data Warehouses im Einsatz
Einige der populärsten Data Warehouses sind Snowflake, BigQuery und Redshift. Snowflake verwendet eine Architektur, die Speicherung und Rechenleistung entkoppelt und dadurch optimale Leistung und Skalierbarkeit bietet. BigQuery ist ein Cloud-basiertes Data Warehouse, das die Speicherung vom Rechnen trennt und sich gut für die Verarbeitung großer Datenmengen eignet. Redshift ist ein leistungsstarkes Cloud-Data-Warehouse mit hoher Speicherkapazität.
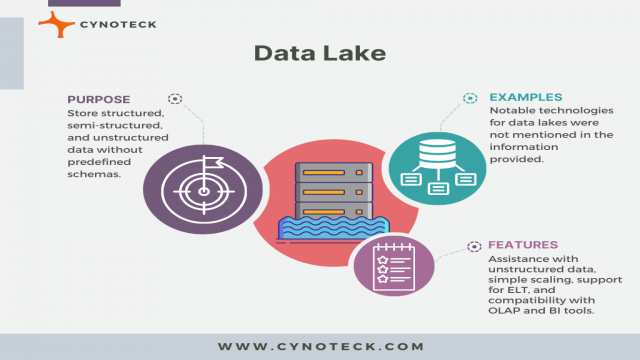
Data Lakes
Ein Data Lake sammelt rohe und verarbeitete Daten aus verschiedenen Quellen und ermöglicht umfangreiche Datenanalysen. Im Gegensatz zu Data Warehouses können Data Lakes unstrukturierte Daten speichern und verwenden kostengünstige Festplatten zur Speicherung. Data Lakes erfordern Fachkenntnisse in Programmiersprachen und Datenwissenschaft, bieten jedoch Skalierbarkeit und eine umfassende Datenanalysemöglichkeit.
Data Lakes im Einsatz
Data Lakes wie Hadoop und Apache Spark eignen sich gut für die Verarbeitung unstrukturierter Daten und werden oft in Kombination mit maschinellem Lernen verwendet. Sie bieten Unterstützung für Extrahieren, Laden und Transformieren (ELT) von Daten und lassen sich gut mit OLAP- und BI-Tools integrieren.
Fazit
Datenbanken, Data Warehouses und Data Lakes erfüllen unterschiedliche Funktionen und werden je nach Anwendungsfall in Unternehmen eingesetzt. Eine moderne Organisation kann von der Integration dieser verschiedenen Datenspeicherlösungen profitieren, um den Wert ihrer Daten zu maximieren. Datenbanken speichern aktuelle Daten, Data Warehouses ermöglichen umfangreiche Datenanalysen und Data Lakes bieten Flexibilität und Skalierbarkeit. Unternehmen sollten die Unterschiede zwischen diesen Lösungen verstehen, um die richtige Wahl für ihre Datenverwaltung zu treffen.
Quelle: Grafik
{kind=link}