

Streaming Daten sind der neueste Trend im Big Data Umfeld. Mit ihnen können komplexe Operationen in Echtzeit auf Datenströmen durchgeführt werden. Aber was genau sind Streaming Daten und welche Frameworks gibt es? In diesem Artikel geben wir dir einen tiefen Einblick in die Welt der Streaming Daten.
Was sind Streaming Daten?
Streaming Daten sind kontinuierlich generierte Daten, die in Echtzeit verarbeitet werden. Sie werden von verschiedenen Systemen wie ERP-Systemen, E-Commerce-Plattformen oder Mobile Apps generiert. Mit Streaming Daten können wir diese Informationen schneller bereitstellen und verarbeiten.

Arten von Streaming Daten
Es gibt zwei Arten von Streaming Daten: natives Streaming und Micro-Batching.
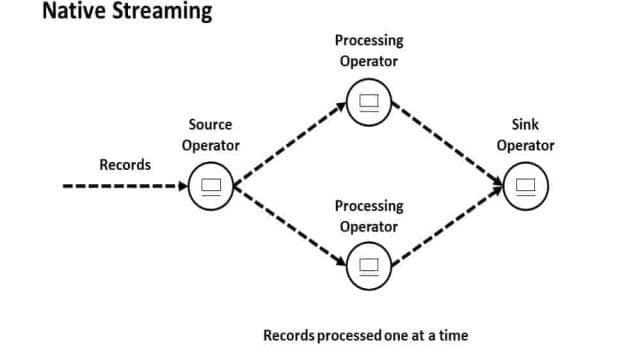
Natives Streaming
Beim nativen Streaming werden die Daten in Echtzeit verarbeitet, ohne auf andere Datensätze zu warten. Das ermöglicht eine geringe Latenz und einen hohen Durchsatz. Bekannte Frameworks für natives Streaming sind Apache Storm, Apache Flink, Kafka Streams und Samza.
Micro-Batching
Beim Micro-Batching werden die Daten in kleinen Batches verarbeitet. Dadurch entsteht zwar ein kleiner Zeitverzug, aber es bietet eine höhere Fehlertoleranz. Apache Spark und Apache Storm Trident sind Frameworks, die Micro-Batching unterstützen.
Beide Arten haben Vor- und Nachteile. Natives Streaming bietet eine geringe Latenz, ist aber schwer fehlertolerant zu machen. Micro-Batching hingegen hat eine höhere Fehlertoleranz, aber eine höhere Latenz.
Wichtige Aspekte bei Streaming Data
Bei der Verarbeitung von Streaming Daten gibt es einige wichtige Aspekte zu beachten:
- Fehlertoleranz: Das Framework sollte in der Lage sein, den Prozess nach einem Fehler wieder aufzunehmen.
- State Management: Das Framework sollte den Zustand der Daten speichern und aktualisieren können.
- Garantierte Verarbeitung: Es gibt verschiedene Methoden der Stream Verarbeitung, von “Atleast-once” bis “Exactly-once”.
- Geschwindigkeit: Die Latenz und der Durchsatz sind entscheidend für die Performance.
- Entwicklungsstand-/Marktreife: Ein erfolgreiches Framework sollte bereits in großen Unternehmen implementiert sein und eine aktive Community haben.
- Weitere Features: Event Time Processing, Zeitfenster Funktionen und die Anwendung von analytischen Modellen sind wichtige Funktionen für komplexe Logik.
Herausforderungen von Streaming Data
Die Verarbeitung von Streaming Daten bringt einige Herausforderungen mit sich. Dazu gehören das Datenvolumen, die Komplexität der Architektur, die Dynamik der Datenströme und die Abfrageverarbeitung. Die Verarbeitung von Datenströmen erfordert eine kontinuierliche Verarbeitung großer Datenmengen aus verschiedenen Quellen. Die Architektur und Überwachung der Infrastruktur kann komplex sein. Zudem sind Datenströme dynamisch und erfordern flexible Verarbeitungsmethoden. Die Abfrageverarbeitung über Datenströme erfordert effiziente Algorithmen und begrenzte Ressourcen.
Streaming Data Frameworks im Vergleich
Es gibt verschiedene Frameworks für die Verarbeitung von Streaming Daten. Hier ein kurzer Vergleich der bekanntesten Frameworks:
| Framework | Vorteile | Nachteile |
|---|---|---|
| Apache Storm (Native Streaming) | Natives Streaming, geringe Latenz, hoher Durchsatz | Kein impliziter Support für Zustandsmanagment, keine Aggregationen oder Windows |
| Apache Spark Structured Streaming (Micro-batching) | Unterstützt Lambda-Architektur, hoher Durchsatz, einfaches API, große Community | Kein nativer Stream, viele Parameter zum Tunen, Stateless |
| Apache Spark Continuous Processing (Native Streaming) | Unterstützt Lambda-Architektur, hoher Durchsatz, einfaches API, große Community | Weniger Funktionen verfügbar, stark in den Anfängen |
| Apache Flink (Native Streaming) | Unterstützt Lambda-Architektur, geringe Latenz, hoher Durchsatz, einfache Handhabung | Späte Entwicklung, kleinere Community, keine Adaption für Batch Modus |
| Kafka Streams (Native Streaming) | Einfache API, gut für Microservices, Exactly Once | Muss mit Kafka verwendet werden, keine riesigen Prozesse möglich |
| Samza (Native Streaming) | Einfache API, gut für Joins von Streams, hohe Fehlertoleranz | Wenige erweiterte Streaming-Funktionen |
Streaming Daten Use Cases im Marketing
Streaming Daten bieten auch im Marketing interessante Use Cases. Zum Beispiel können sie zur Personalisierung im E-Commerce Checkout verwendet werden. Durch die Verarbeitung der neuesten Daten in Echtzeit können wir die richtigen Empfehlungen im Checkout-Prozess geben. Auch für Trigger Marketing Kampagnen und Streaming ETL gibt es spannende Anwendungsfälle.
Streaming Analytics
Streaming Analytics ermöglicht die Ausführung von Machine Learning Modellen im Stream. Dabei werden Modelle auf die eintreffenden Daten angewendet und in einem Feature Store gespeichert. Dadurch können personalisierte Empfehlungen in Echtzeit generiert werden.
Streaming Daten bieten viele Herausforderungen, aber auch viele Chancen. Wenn du mehr über Streaming Daten erfahren möchtest, kontaktiere uns! Wir bieten umfangreiche Beratung im Bereich Data Science und Data Engineering an.
Weitere interessante Artikel:
- Was sind die Vorteile des Unity Catalogs von Databricks?
- Der Databricks Unity Catalog einfach erklärt
- Large Language Model Fallbeispiele
- Kundenwert: wie wertvoll ist jeder einzelne Kunde?
- Aufbau eines Data Science Teams