

Einige von euch werden diese Situation sicherlich kennen: Ihr habt eure Webseite, euren Blog oder euren Internetshop liebevoll eingerichtet. Stunden und Tage wurden dafür investiert und die Webseite für Besucher zugänglich gemacht. Und dann das: Niemand kommt vorbei.
Wie auch? Niemand surft im Internet, indem man auf “gut Glück” eine URL in die Adresszeile des Browsers eingibt. Die Leute benutzen Suchmaschinen wie Google oder Bing. Nicht umsonst hat sich das Wort “googlen” als Synonym für “etwas im Internet suchen” durchgesetzt.
Daher ist es natürlich wichtig, dass man auch von Suchmaschinen gefunden wird. Denn was Google nicht kennt, das kann Google nicht zeigen. Und da Google in Deutschland der absolute Marktführer ist, werde ich auch im Folgenden den Fokus auf den Suchmaschinen-Primus legen.
Kennt Google dich?
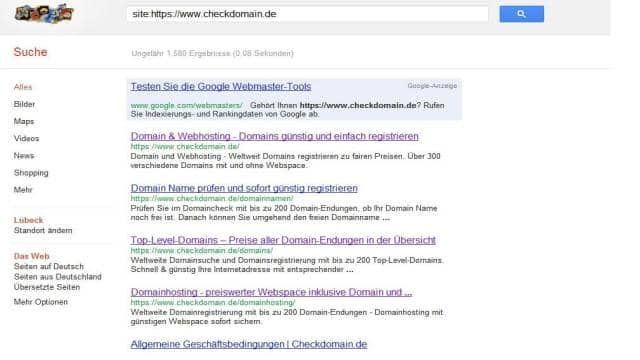
Am besten prüft man zu Beginn, ob Google die eigene Webseite wirklich kennt. Hierfür begebt ihr euch auf www.google.de und gebt dort “site:http://deine-domain.tld” ein. Nun bekommt ihr eine Übersicht über alle Seiten und Unterseiten eurer Domain, die Google bekannt sind.

Wenn ihr hier Einträge findet, kennt euch Google. Wenn allerdings trotzdem keine Besucher auf eure Seite kommen, solltet ihr euch eventuell mit den Grundlagen der Suchmaschinenoptimierung auseinandersetzen. Aber gehen wir jetzt erstmal von dem Fall aus, dass hier keine Einträge stehen und euer Internetauftritt leider Google nicht bekannt ist.
Schauen wir also erstmal, an was es liegen kann. Eventuell habt ihr Google von der Indexierung eurer Seite abgehalten. Dafür gibt es mehrere Möglichkeiten:
Der Meta-Tag “robots” blockt Google
Am besten checkt ihr dafür den Quelltext eurer Seite.
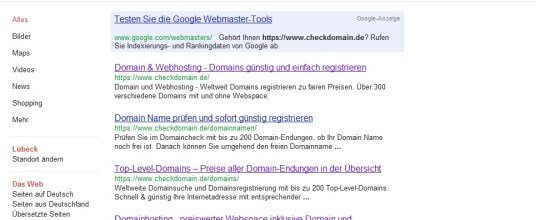
Hier muss – wie im Screenshot – im Attribut “index, follow” stehen. Sollte stattdessen ein “noindex, nofollow” zu finden sein, solltet ihr das umgehend in den Einstellungen eurer Seite ändern. Dieser Meta-Tag steuert nämlich den Zugang von Suchmaschinen-Bots. Wenn das behoben wurde, gilt es abzuwarten und eventuell die Site-Abfrage in etwa zwei Wochen noch einmal zu wiederholen.
Die robots.txt
Vielleicht habt ihr eine robots.txt auf euren FTP-Server hochgeladen. Dort legt man die Regeln der Indexierung für die Bots/Crawler fest. Wie man die robots.txt vernünftig nutzt, kann man bei den SEO-Trainees wunderbar nachlesen.
Aufrufen könnt ihr eure robots.txt ganz einfach im Browser. Gebt “http://deine-domain.tld/robots.txt” ein und ihr bekommt gegebenenfalls so ein Bild:
Sollte sich in eurer robots.txt nur Folgendes wiederfinden:
user-agent: *
disallow: /blockt ihr alle Crawler für eure gesamte Seite – und natürlich auch den Crawler von Google. Ändert daher den Eintrag in:
user-agent: *
disallow:oder auch in:
user-agent: *
disallow: /Pfad-der-nicht-in-den-google-index-soll/ (z.B. /admin/)Sollte allerdings auch die robots.txt nicht der Grund dafür sein, dass Google eure Internetseite nicht kennt, müssen wir weitergraben.
Das Google Webmaster-Tool
Einer der einfachsten Wege ist es, sich beim Google Webmaster-Tools anzumelden. Dazu wird lediglich ein Google-Konto benötigt. Hier könnt ihr euch anmelden.
Für die Anmeldung gibt es mehrere Wege, auf die ich ebenfalls in einem anderen Artikel tiefer eingehe. Nach einer erfolgreichen Anmeldung wird Google auf alle Fälle seinen Bot losschicken und die Seite sollte recht schnell im Google-Index zu finden sein. Prüft das ebenfalls mit der Site-Abfrage nach einigen Tagen und ich wette, dann findet ihr die ersten Seiten bei Google wieder. Ob ihr dann allerdings auch für die richtigen Suchbegriffe bei Google gefunden werdet, das steht auf einem anderen Blatt 😉
Haben euch die Tipps etwas gebracht oder habt ihr Ergänzungen? Dann freue ich mich auf eure Kommentare.
Du suchst nach einer kostenlosen Homepage? Mit unserem Homepage-Baukasten bist du in der Lage schnell ansprechende Websites zu erstellen.